
The first product I shipped as a founder did not fail on launch day. It failed on day 41.
It went live on a Tuesday in 2023, the kind of launch where the check-list clears and three people congratulate each other by text message. Five weeks later the usage graph bent in a direction none of us had designed for, a regulator in a jurisdiction we were not watching changed a rule, and the client’s internal champion — the person who had fought for the project — took another job. By then the external engineering team was thirty days into their next engagement. The client called us. We had been the consultants on the deal. We had also been explicit, in the statement of work, that we did not do post-launch support.
We took the call anyway. We spent four weeks resolving what was, in fairness to the engineering team that shipped it, their contractual victory and our uncontracted problem. And at the end of it I wrote down, for the first time, the sentence that became the operating premise of this company:
The division of labor that lets consultants write the strategy, designers make the wireframes, engineers build the code, and operations vendors keep it running — that division itself is the problem.
This post is about why we stay. It is also about why we think the rest of the industry’s answer — “delivery” is a moment, “maintenance” is a separate contract — is the thing that causes most technology projects to quietly stop mattering.
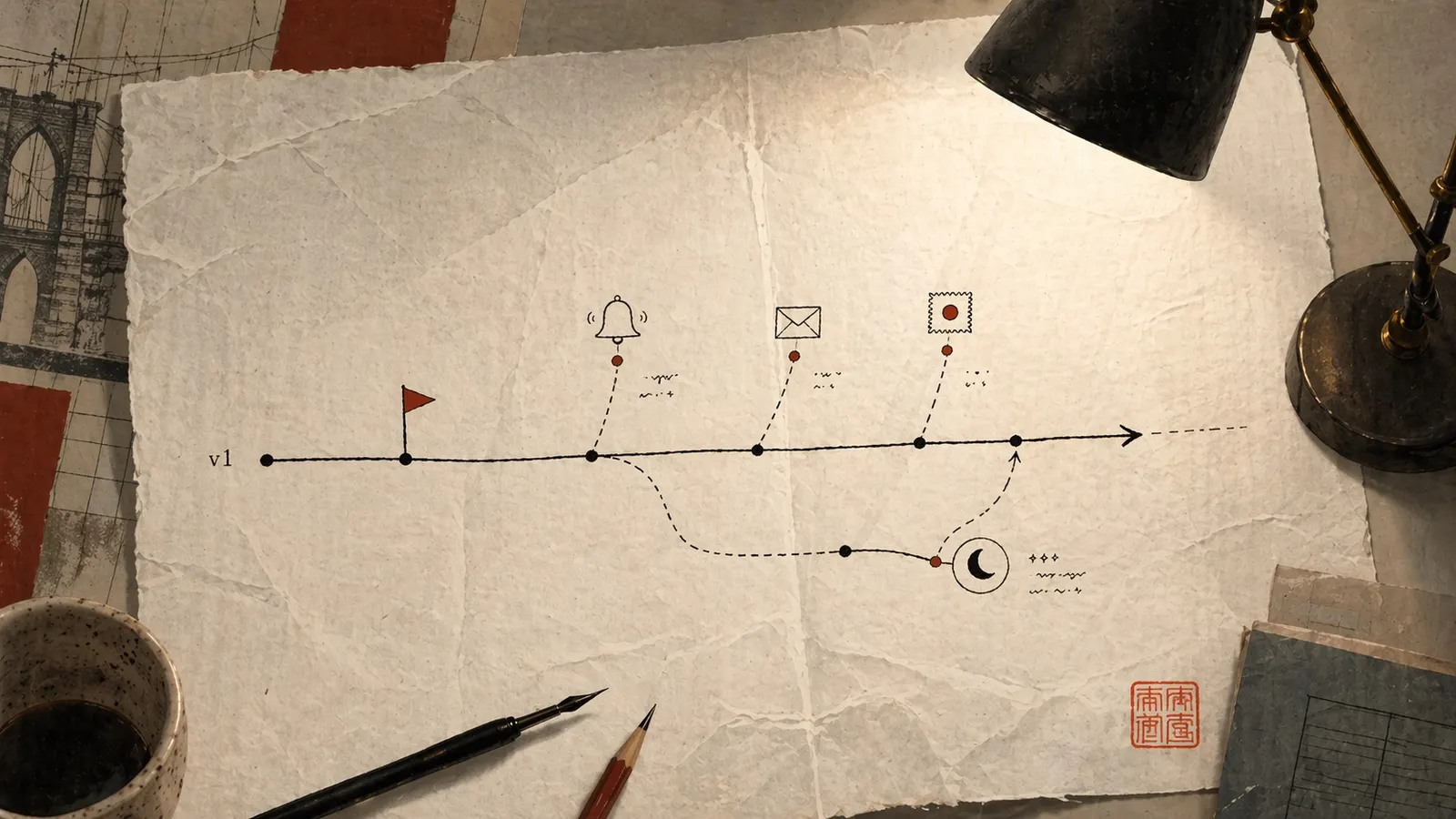
The cost of handing off a warm product to strangers
In the first six months after launch, more real things happen to a product than in the entire year before it. Users click in places no one designed for. Monitoring pages someone at 3am for the first time. Support starts hearing questions we never imagined. A regulator moves. A partner API changes its authentication model. A sister product at the same company launches and redirects the attention of the only internal stakeholder who was watching.
Every one of those events is a lesson. Most of those lessons only exist in the four weeks around when they happen — if nobody with context is watching the product, the lesson dissolves and the product accrues quiet debt instead: a metric drifting down without explanation, a small feature nobody uses that nobody remembers commissioning, a support script that pastes the same answer to a question that was fixable in an afternoon.
If the design and engineering teams dissolve at v1, all those real events have nowhere to land. What happens in practice is that the client’s internal team, who did not build the thing and often does not know why it was built the way it was built, inherits a stack of Jira tickets and a PagerDuty schedule. Within a quarter, most of the lessons are lost. Within two quarters, the product’s trajectory is decided by whoever happens to be on the rotation, not by anyone who remembers what it was trying to be.
We have watched this happen from the consulting seat. It is the single most common reason good plans ship and then stop being good plans.
What this looks like in practice
Every launched project we are part of has a resident engineer and a product manager who directly own it for at least 12 weeks after launch. Monitoring, growth instrumentation, compliance renewals, point releases — all of it sits with them. This is not a “maintenance contract.” This is part of delivery.
// Default engagement shape
const shape = {
phase_0: 'Consulting', // weeks 1–3
phase_1: 'Design', // weeks 2–8
phase_2: 'Build', // weeks 6–18
phase_3: 'Launch', // week 18
phase_4: 'Operate', // week 18 → ongoing ★
};The starred line is what this post is actually about.
“Delivery” is not a moment. It is a continuous state — software still running, still used, still being changed.
Three principles, each of which is a contractual commitment
Saying we stay is free. Structuring the company so staying is the default — that is what I want to describe.
1. We sign up to the client’s metric, not to ours
A traditional engineering vendor’s success criterion is “delivered on spec, on time, on budget.” That is a local optimum for the vendor and often an irrelevance for the client. Our engagements define one quantitative metric that belongs to the client — “monthly active guides using the device,” “approval-cycle time per creative review,” “p99 sync latency” — and we report against it every two weeks for at least a full quarter past launch. If it is not moving, our engagement is not working, regardless of the deliverable checklist.
This means we sometimes refuse work. If a prospective client cannot name a post-launch metric they would judge the project by, that is a signal the project is not ready; we say so out loud.
2. The engineer who built it is the engineer who operates it for 12 weeks minimum
This is unpleasant to staff. It means we cannot fully load an engineer onto the next project until the last one has proven itself. It produces a visible gap on the resourcing board that competitive shops avoid by rotating people immediately.
We take the gap. The alternative — handing a warm product to someone reading the code for the first time — produces the “hired to fix what the previous vendor shipped” engagement that dominates this industry. We would rather earn fewer engagements and keep each one past the critical window.
3. We write down what we learn, in the open, with dates
Operate-phase learning that lives only in Slack DMs between the client and us is not learning — it is expiring context. Every on-call postmortem, every metric movement, every change in the product’s assumptions gets written into a document the client owns and we append to. Twelve weeks in, that document is typically the most accurate description of the product that exists anywhere — more accurate than the PRD it launched from.
The purpose is not process. The purpose is that when, eventually, the product is handed fully to the client’s internal team, they inherit the reasoning, not just the codebase.
Two places this shows up concretely
A museum hardware partner
We built the firmware and platform layer for a museum hardware partner’s next-generation smart tour-guide device in 2024. The device was designed for museums, a context where the distribution of “how a visitor behaves” is genuinely strange — people walk away mid-sentence, stand in places with no RF line-of-sight, cluster in ways that overwhelm a naive Bluetooth mesh.
The launch firmware passed the pre-launch test protocol. It passed because the protocol had been written by the same engineers who wrote the firmware, which is a failure mode we did not see until week three of real deployments, when the museum’s floor staff started reporting a pattern of silent device-to-device handoff failures in the one corridor where three major exhibits converged. Nothing in the pre-launch tests had simulated three simultaneous visitor clusters with partially-overlapping RF.
Because we had a resident engineer inside the operate phase, that pattern turned into a firmware hotfix in four working days. Because we had a post-launch metric contractually defined (silent-handoff rate as observed in production telemetry), the fix had something to measure itself against. Because we had written down the operating assumptions as we went, the hotfix could be reviewed against the original reasoning rather than against folk memory.
None of that is engineering heroism. It is the absence of a vendor seam at the moment where a vendor seam would have cost the client a quarter of trust with museum curators — who, in that industry, do not give trust back quickly.
Kunwu (堃悟信息)
With Kunwu we were the consultants, not the engineers. The engagement was a strategic review of an advertising-law review platform — technical architecture, vendor selection, MVP scoping. The kind of project where the deliverable is a document and most firms leave on the day the document is signed.
We stayed, in a lighter form, through the first twelve weeks of the platform’s build-out by a different engineering vendor. Not as second-guessers; as reviewers who already knew why specific architectural decisions had been made. Two of those decisions came under pressure in weeks six and nine of the build when the engineering team wanted to take what looked like obvious shortcuts. Because we had written the decisions down with reasons, we were able to re-anchor the conversation in forty-five minutes instead of the two weeks it would have taken to re-derive the analysis.
The platform shipped on schedule. More importantly, it shipped with the architectural spine it had been designed around, not a degraded version of it.
What this means for clients and for future teammates
For clients reading this: the thing you are buying from us, functionally, is not just a v1. It is the presence, past v1, of the people who built v1. The pricing reflects that; the engagement structure reflects that; the resourcing constraint reflects that. If your procurement process treats “build” and “operate” as separate line items from separate vendors, we are probably a poor fit — not because the work is worse, but because the fee structure does not survive the split.
For engineers, designers, and operators reading this because you are thinking about joining: the cost of this commitment is personal. We staff more slowly than our pipeline would otherwise permit because we will not rotate a person off a warm product to chase a new one. In return, the work does not evaporate six weeks after it ships. You see whether the thing you built actually mattered.
Staying is a discipline, not a virtue. It is the reason the other three phases are worth doing.